随着容器化和微服务架构的广泛应用,Kubernetes已成为云原生应用部署和管理的事实标准。在Kubernetes环境中,日志作为系统运行状态、应用行为和故障排查的重要依据,其采集、存储与处理显得尤为重要。本文将探讨Kubernetes下日志采集、存储与处理的技术实践,重点介绍数据处理和存储服务的实现方案。
一、日志采集技术实践
在Kubernetes中,日志采集面临容器动态调度、多副本部署等挑战。常见的采集方式包括:
- Sidecar模式:通过为每个Pod添加一个日志采集容器(如Fluentd、Filebeat),将应用日志输出到共享卷,再由Sidecar容器读取并发送至日志存储系统。
- DaemonSet模式:在集群每个节点部署日志采集代理(如Fluent Bit、Logstash),采集节点上所有容器的日志文件。
- 应用直接推送:应用通过SDK或API直接将日志发送到日志服务(如日志服务商或自建服务)。
实践中,DaemonSet模式因资源消耗低、部署简单而广泛使用,而Sidecar模式适用于多租户或日志格式复杂的场景。
二、日志存储服务方案
日志存储需考虑可扩展性、持久性和查询性能。主流方案包括:
- 集中式日志存储:使用Elasticsearch、Loki等作为日志存储后端。Elasticsearch支持全文检索和复杂分析,适合大规模日志;Loki基于标签索引,存储效率高,与Grafana集成良好。
- 对象存储:将日志归档至云服务商的对象存储(如AWS S3、阿里云OSS)或自建MinIO,适用于冷数据存储,成本较低。
- 时序数据库:若日志含时间序列数据(如指标日志),可选用InfluxDB或Prometheus,支持高效时间范围查询。
存储方案选择需结合日志量、查询需求和成本。例如,热数据存Elasticsearch,冷数据转存对象存储。
三、数据处理服务实践
日志处理包括解析、过滤、富化和转发,常见工具如下:
- 流处理引擎:使用Flink或Kafka Streams对日志流进行实时处理,如提取关键字段、异常检测。
- 日志处理代理:Fluentd或Logstash支持插件化处理,可解析JSON、正则匹配、添加元数据(如Pod标签)。
- 服务网格集成:通过Istio等服务网格采集网络日志,并结合Envoy Access Log进行流量分析。
数据处理环节可结合Kubernetes元数据(如Pod名称、命名空间)富化日志,提升可观测性。例如,Fluentd通过Kubernetes Metadata Filter插件自动添加Pod信息。
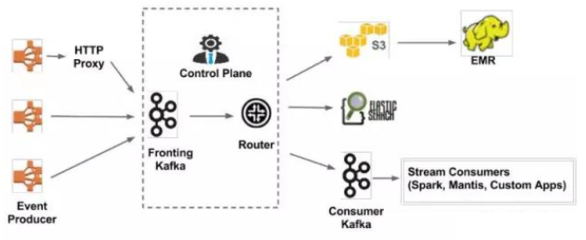
四、完整架构示例
一个典型的Kubernetes日志流水线包括:
- 采集层:DaemonSet部署Fluent Bit,采集节点日志并初步过滤。
- 处理层:日志发送至Kafka消息队列,由Flink消费并进行实时解析。
- 存储层:处理后的日志存入Elasticsearch,供Kibana可视化;同时归档至S3。
- 告警与监控:通过Elasticsearch Alerting或Prometheus检测日志异常,触发告警。
五、最佳实践与挑战
- 资源管理:为日志采集组件设置资源限制,避免影响应用性能。
- 日志旋转与保留:配置日志文件大小和保留策略,防止磁盘溢出。
- 安全与合规:加密日志传输(TLS/SSL),实施访问控制,满足审计要求。
- 多云与混合云:使用统一日志格式和采集标准,便于跨环境管理。
Kubernetes下的日志技术实践需结合采集、存储与处理,形成端到端的流水线。通过选择合适的工具和架构,可实现高效、可靠的日志管理,为运维和开发提供强大支持。