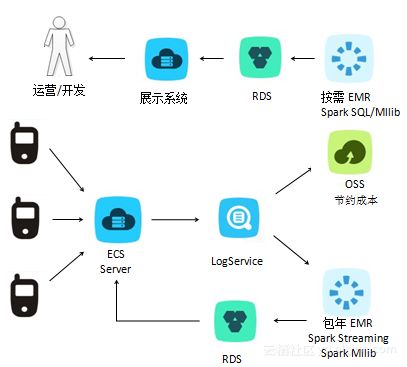
阿里云E-MapReduce(EMR)作为一款全托管的大数据平台,为用户提供了弹性、可靠、高效的数据处理与存储解决方案。结合最佳实践与完善的容灾策略,可以最大化地保障业务的连续性和数据的安全性。
一、数据处理与存储服务核心架构
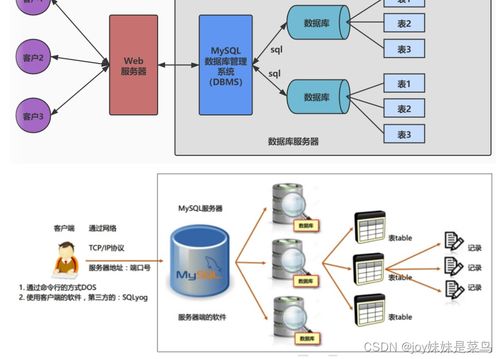
阿里云EMR的核心优势在于其深度集成的开源大数据生态(如Hadoop、Spark、Flink、Hive、HBase等)与阿里云基础设施(如ECS、OSS、VPC)的无缝对接。数据处理通常遵循“采集-存储-计算-分析-服务”的流水线,而存储服务则依赖OSS的对象存储、云盘块存储以及EMR集群内的HDFS,形成分层、冷热分离的存储体系。
二、最佳实践
- 集群规划与资源配置
- 节点选型:根据计算密集型(如Spark SQL分析)或内存密集型(如Flink实时处理)任务,选择合适ECS实例规格(如计算型c7、内存型r7)。主节点选择高可用配置,核心节点与任务节点按需弹性伸缩。
- 存储选择:将永久性数据、备份数据存储在OSS中,利用其高持久性和低成本;将中间计算数据、热数据存放在集群HDFS或本地SSD云盘,以获取更高IO性能。
- 网络与安全:部署在专有网络VPC内,通过安全组精确控制访问。使用RAM进行细粒度的权限管理,对敏感数据启用加密(如RDS数据源加密、OSS服务端加密)。
- 数据处理流程优化
- 计算引擎选择:批处理首选Spark,交互查询使用Presto/Impala,实时流处理采用Flink,图计算使用GraphCompute,根据场景选择最适配引擎。
- 数据分层与格式:建立ODS(原始数据层)、DWD(明细数据层)、DWS(汇总数据层)、ADS(应用数据层)的数据仓库模型。优先使用列式存储格式(如ORC、Parquet)以提升压缩率和查询性能。
- 作业调优:合理设置Spark的executor数量、内存、核数;利用动态资源分配;对Hive/Spark SQL进行表分区、分桶、使用合适的Join策略。
- 运维与成本管理
- 弹性伸缩:配置基于负载(如YARN队列资源使用率)或时间的自动伸缩规则,在业务高峰时自动扩容,空闲时缩容以节约成本。
- 监控告警:全面利用云监控服务,对集群核心指标(如CPU使用率、HDFS存储使用率、节点健康状态)设置告警。通过EMR Doctor进行深度智能运维诊断。
- 作业调度:使用EMR Workflow或Airflow进行复杂工作流的编排、调度和依赖管理。
三、容灾与高可用策略
- 集群级高可用与容灾
- 多主节点部署:在创建集群时启用高可用模式,EMR会自动部署多个Master节点(如HDFS NameNode, YARN ResourceManager, HBase HMaster),避免单点故障。
- 跨可用区部署:将集群的核心节点(Master、Core)部署在同一地域的不同可用区(AZ),实现机房级别的容灾。利用VPC和高速通道保障跨AZ网络性能。
- 数据备份与恢复:
- HDFS数据:定期将HDFS关键数据同步到OSS(使用DistCp工具或通过EMRFS直接写入OSS)。可设置生命周期策略将OSS备份数据转为归档存储以降低成本。
- 元数据:对Hive Metastore、Ranger策略库等重要元数据,定期导出备份至OSS或RDS,并测试恢复流程。
- 集群快照:对于重要集群状态,考虑制作自定义镜像或记录完备的集群配置脚本,以便灾难后快速重建。
- 数据存储层容灾
- OSS跨区域复制:为核心备份数据或结果数据在OSS上配置跨区域复制(CRR)功能,将数据异步复制到另一个地域的Bucket中,实现地理级别的数据容灾。
- 数据库RDS多可用区:若EMR业务依赖云数据库RDS,应使用RDS的多可用区实例,其主备实例位于不同机房,提供高可用保障。
- 业务连续性计划
- 主动-被动灾备:在另一个地域部署一套备用的EMR集群(规模可缩小),定期从主地域OSS同步数据和元数据。主集群故障时,可快速拉起或扩容备用集群接管业务。
- 流处理容灾:对于Flink等流作业,启用Checkpoint并将状态后端设置为OSS,确保作业失败后能从最近的一致状态恢复。
- 定期演练:定期模拟节点故障、可用区中断等场景,测试数据恢复、集群重建和作业切换流程,验证并完善容灾预案。
四、
构建基于阿里云EMR的可靠数据处理与存储服务体系,需要将科学的架构规划、持续的性能优化与周密的容灾设计相结合。通过遵循上述最佳实践,并实施跨可用区、跨地域的多级容灾策略,企业能够在享受EMR带来的强大计算能力与敏捷性的确保数据资产的安全与业务服务的持续稳定,从容应对各种潜在风险与挑战。