引言
在当今大数据时代,高效的数据存储与处理技术是企业数字化转型的核心驱动力。Hadoop作为开源分布式计算框架的基石,以其高容错性、高扩展性和低成本优势,成为处理海量数据的首选方案。CSDN(中国开发者网络)作为国内领先的IT技术社区和综合服务平台,其背后庞大的用户行为数据、内容数据及交互数据的管理,离不开对Hadoop技术的深度应用。本文将系统阐述Hadoop的数据存储与处理核心流程,并结合CSDN的实际应用场景,探讨其数据处理与存储服务的实践。
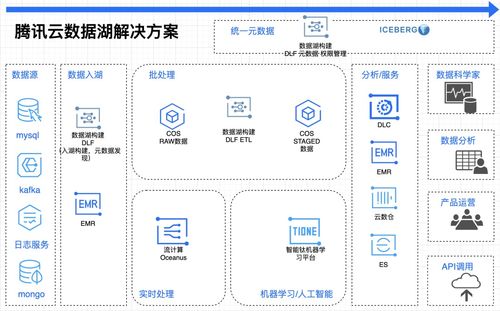
第一部分:Hadoop数据存储流程
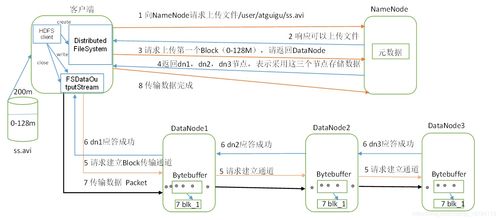
Hadoop的数据存储主要由其分布式文件系统——HDFS(Hadoop Distributed File System)完成。其设计目标是存储超大规模数据集,并在商用硬件集群上提供高吞吐量的数据访问。
核心流程如下:
1. 文件分块: 当客户端上传一个文件时,HDFS首先将其切分为固定大小的数据块(Block,默认128MB或256MB)。分块存储便于并行处理、简化存储管理并适应大规模数据。
2. 元数据管理: 由NameNode负责管理文件系统的命名空间(如目录树、文件到数据块的映射)以及数据块在集群中的位置信息。这些信息(即元数据)常驻内存以保证快速访问。
3. 数据写入与复制:
* 客户端与NameNode通信,获取可写入的数据节点(DataNode)列表。
- 客户端将数据块直接写入列表中的第一个DataNode,该节点接收数据的会将其流水线式地复制到列表中的其他节点,默认创建3个副本。
- 这种多副本机制是HDFS实现容错和高可靠性的关键,确保部分硬件失效时数据不丢失。
- 数据存储与心跳维护: DataNode将数据块以本地文件的形式存储在磁盘上,并定期向NameNode发送心跳信号和数据块报告,以确认其存活状态及存储的数据块列表。
流程特点: 写一次、读多次;移动计算而非移动数据(将计算任务分发到数据所在节点)。
第二部分:Hadoop数据处理流程
数据处理主要由MapReduce计算模型完成,它将复杂的分布式计算抽象为Map和Reduce两个核心阶段。
核心流程如下:
1. 输入与分片: 输入数据(通常来自HDFS)被逻辑切分为多个输入分片。每个分片由一个Map任务处理,分片大小通常与HDFS的数据块大小一致,以实现数据本地化计算。
2. Map阶段:
* 每个Map任务读取一个输入分片,并逐条调用用户定义的map()函数。
map()函数处理输入的键值对,并输出一系列中间键值对。这些中间结果首先被写入内存缓冲区。
- Shuffle与Sort阶段(关键桥梁):
- 当缓冲区达到阈值,数据会被溢写到本地磁盘,并在写入前根据中间键进行分区(决定由哪个
Reduce任务处理)和排序。
- 所有
Map任务完成后,每个Reduce任务通过HTTP协议从各个Map任务的磁盘上拉取属于自己的那部分分区数据,这个过程称为Shuffle。
Reduce任务将拉取到的数据进行归并排序,使得相同键的记录聚集在一起。
- Reduce阶段: 排序后的中间数据被输入到用户定义的
reduce()函数中。reduce()函数对每个键及其关联的值列表进行处理,并产生最终的输出结果。 - 输出: 最终的输出结果被写入HDFS,通常每个
Reduce任务生成一个独立的输出文件。
流程特点: 批处理、高吞吐量;通过Shuffle阶段实现数据的重新分发与聚合。
第三部分:CSDN的数据处理和存储服务实践
CSDN平台承载着数千万开发者的技术博文、问答、课程、动态等海量非结构化与半结构化数据。其数据处理与存储服务深度集成了Hadoop生态系统。
1. 数据存储服务:
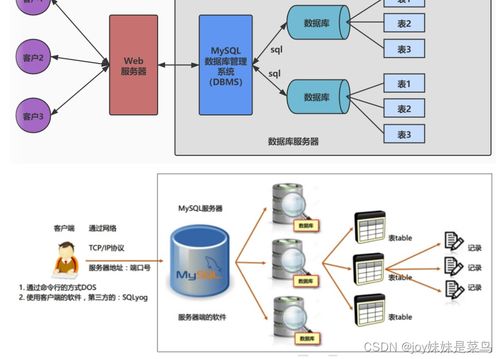
原始数据湖: 利用HDFS构建企业级数据湖,统一存储来自Web服务器、App、日志系统等各类原始数据(如用户点击流、内容发布记录、搜索日志)。HDFS的廉价扩展能力完美支撑了CSDN数据量的持续快速增长。
结构化数据仓库: 在HDFS之上,通过Hive或Spark SQL建立数据仓库,将原始日志进行ETL清洗和转换后,以结构化的表形式存储,支撑BI报表、用户画像分析等下游应用。
2. 数据处理服务:
离线批量处理: 对于用户行为分析、内容质量统计、个性化推荐模型的离线训练等延迟不敏感的任务,CSDN使用MapReduce或更高效的Spark引擎进行每日/每周的批量计算。例如,通过处理前一天的日志,计算热门技术话题排行榜。
实时数据处理: 对于监控告警、实时推荐、动态流更新等低延迟场景,CSDN会结合使用Storm、Flink或Spark Streaming等流处理框架,它们可与Hadoop生态无缝集成,从Kafka等消息队列中消费数据,进行实时处理后将结果存入HBase或HDFS。
* 数据挖掘与机器学习: 基于存储在HDFS上的海量历史数据,利用Mahout或Spark MLlib等分布式机器学习库,进行社区热点发现、用户聚类、内容自动分类等复杂分析,驱动产品智能化。
结论
Hadoop通过HDFS和MapReduce等核心组件,定义了经典的大数据存储与批处理范式。其清晰的存储流程(分块-复制-分布式存储)与处理流程(分片-Map-Shuffle-Reduce)为处理PB级数据提供了可扩展且可靠的解决方案。在CSDN这样的实际业务平台中,Hadoop已不仅仅是单一工具,而是演变为其大数据基础设施的核心。CSDN通过将Hadoop与生态系统中其他工具(如Hive、Spark、HBase)有机结合,构建了一套从数据摄入、存储、批量处理到实时计算和智能分析的全链路数据处理与存储服务体系,从而有效地将数据资产转化为产品价值与用户体验,服务广大开发者社区。
随着云原生和实时化趋势的发展,Hadoop生态也在不断演进(如YARN资源调度、容器化部署),但其核心的分布式思想与流程,依然是构建大型数据处理系统的宝贵蓝图。