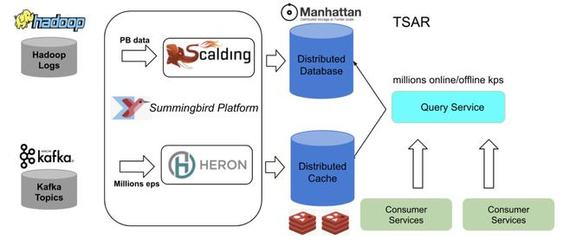
随着数据规模的指数级增长,Twitter在数据处理和存储服务方面面临诸多挑战。为提升系统效率、可扩展性和实时性,Twitter决定弃用原有的Lambda架构,转向基于Kafka和现代数据流技术的新架构。这一转变不仅优化了数据处理流程,还为存储服务带来了显著的性能提升。
Lambda架构虽然在过去为Twitter提供了批处理和实时处理的结合方案,但其复杂性高、维护成本大,且难以适应快速变化的数据需求。例如,Lambda需要维护两套独立的代码库和基础设施,导致数据处理延迟和系统资源浪费。因此,Twitter选择弃用Lambda,以实现更简洁、高效的架构设计。
新架构的核心组件是Kafka,一个分布式的事件流平台。Kafka以其高吞吐量、低延迟和可扩展性著称,能够处理Twitter海量的实时数据流。通过Kafka,Twitter可以轻松地捕获、存储和传输数据,例如用户推文、互动事件和系统日志,从而为下游应用提供一致的数据源。这不仅简化了数据管道,还减少了数据冗余和错误。
Twitter还集成了其他数据流技术,如Apache Flink或Apache Samza,用于实时数据处理和分析。这些工具允许Twitter在数据流入时进行复杂的转换、聚合和过滤,无需依赖批处理延迟。例如,实时监控用户行为、检测异常活动或生成动态推荐,都得益于这种数据流架构的即时响应能力。
在存储服务方面,新架构结合了分布式数据库和云存储解决方案,提升了数据的可靠性和访问速度。通过将数据流与存储层紧密集成,Twitter能够实现更高效的数据持久化、备份和检索,支持高并发查询和机器学习应用。这种架构还增强了系统的容错性,确保在节点故障时数据不会丢失。
Twitter的这一架构转型标志着其数据处理与存储服务的现代化进程。通过弃用Lambda并启用Kafka和数据流新架构,Twitter不仅降低了运维成本,还提升了用户体验,为未来大数据和AI驱动的创新奠定了坚实基础。随着技术的不断演进,这一举措有望成为行业标杆,激励更多企业优化其数据处理策略。