在大数据生态系统中,Apache Hive作为基于Hadoop的数据仓库工具,扮演着至关重要的角色。它不仅提供了类似SQL的查询语言(HiveQL),方便数据分析师进行数据查询与分析,其高效的数据存储格式与强大的数据处理能力更是其核心优势。本文将系统性地介绍Hive的数据存储格式、数据处理流程以及其在数据存储服务中的定位。
一、 Hive数据存储格式
Hive的数据存储格式直接决定了数据的读写效率、存储空间利用率和查询性能。Hive支持多种存储格式,主要分为两大类:行式存储和列式存储。
- 行式存储格式
- 文本文件(TextFile):这是Hive默认的存储格式。数据以纯文本形式存储,每行一条记录,字段间通常由分隔符(如逗号、制表符)隔开。其优点是通用性强,人类可读,易于与其他工具交换数据。缺点是存储空间占用大,不支持块压缩,查询效率较低,因为即使只查询少数几列,也需要读取整行数据。
- SequenceFile:一种Hadoop生态系统中的二进制键值对存储格式。它将数据序列化后存储,支持块压缩,比TextFile更节省空间,且是Hadoop原生格式,兼容性好。但其本质上仍是行式存储,对于需要全表扫描或只访问部分列的分析查询,效率提升有限。
2. 列式存储格式
列式存储将数据按列而非按行组织,特别适合数据分析场景,因为大多数分析查询只涉及表中的部分列。
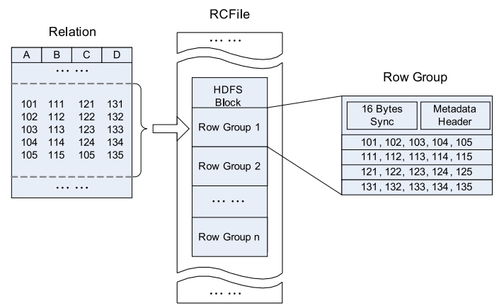
- ORC(Optimized Row Columnar):由Hive社区专门为Hive设计的高效列式存储格式。它提供了极高的压缩比(通过Run-Length Encoding、字典编码等算法)和快速的读取性能。ORC文件内部将数据划分为Stripes(条带),每个Stripe包含索引、数据行和footer。索引允许Hive快速跳过不相关的数据块,极大地提高了查询速度,尤其是带谓词(WHERE条件)的查询。ORC是Hive场景下最推荐使用的格式之一。
- Parquet:另一种广泛使用的、与语言和框架无关的列式存储格式。它源自Google的Dremel论文,被Spark、Impala、Presto等多种大数据处理引擎原生支持。Parquet支持复杂的嵌套数据结构,并具有优秀的压缩和编码方案。在Hive与Spark等组件共存的混合环境中,Parquet因其出色的跨平台兼容性而成为理想选择。
选择建议:对于ETL过程中的中间临时表或需要频繁全字段访问的场景,可考虑行式存储。而对于数仓中的核心事实表、维度表,进行大规模分析查询时,强烈推荐使用ORC或Parquet格式。
二、 Hive数据处理流程
Hive的数据处理并非在自身进程中完成,其本质是一个“翻译器”和“协调者”。
- 解析与编译:用户提交HiveQL语句(如SELECT, JOIN, GROUP BY)。Hive的Driver组件首先对SQL进行解析(Parse),生成抽象语法树(AST)。然后进行语义分析和编译(Compile),将AST转换为一系列的逻辑操作(逻辑执行计划)。
- 优化:优化器(Optimizer)对逻辑执行计划进行优化,例如谓词下推、列裁剪、分区裁剪等。优化的核心思想是尽可能早地过滤掉无关数据,减少后续阶段需要处理的数据量。例如,对于列式存储,优化器会确保只读取查询涉及的列。
- 执行计划生成:优化后的逻辑计划被转换成物理执行计划,即一系列由MapReduce、Tez或Spark任务组成的DAG(有向无环图)。Hive早期默认使用MapReduce,但其Tez或Spark on Hive引擎因更优的内存管理和DAG执行模型,能提供更低的延迟和更高的吞吐量。
- 任务执行与结果返回:Hive将物理执行计划提交给底层的计算引擎(如YARN上的Tez/Spark)。计算引擎调度任务在Hadoop集群上执行,从HDFS读取数据,经过Map、Shuffle、Reduce等阶段处理,最终将结果写回HDFS或直接返回给客户端。
整个流程体现了Hive“读时模式”(Schema-on-Read)的特点:数据存储时无需严格定义格式,在查询时根据表定义进行解析,提供了极大的灵活性。
三、 Hive作为数据存储与处理服务
在企业的数据架构中,Hive通常定位为中心化的数据仓库存储与批量处理服务。
- 存储服务角色:Hive的表数据实际存储在HDFS上,Hive Metastore(元数据存储,通常使用MySQL等关系数据库)则集中管理所有表的元信息(如表名、列名、数据类型、分区信息、数据存储路径等)。这使得多个用户和计算引擎(如Spark、Presto)可以通过统一的元数据视图访问和共享同一份数据,避免了数据孤岛。Hive Metastore是Hadoop生态中许多组件共享元数据的事实标准。
- 处理服务角色:Hive提供了稳定、可靠的批量SQL处理能力。它擅长处理TB/PB级别的历史数据离线分析、复杂的ETL作业(数据清洗、转换、加载)、定期报表生成等场景。虽然其基于磁盘的批处理模式导致延迟较高(分钟到小时级),不适合实时查询,但其吞吐量高、容错性强、成本低廉的优势在离线分析领域无可替代。
- 服务化集成:在现代数据平台中,Hive常作为底层存储与计算层,与调度系统(如Airflow、DolphinScheduler)、数据湖框架(如Hudi、Iceberg)、即席查询引擎(如Presto, Impala)以及BI工具(如Tableau, Superset)紧密集成,共同构成完整的数据服务栈。
Hive通过其灵活多样的数据存储格式(尤其是高效的列式格式ORC/Parquet)、将SQL翻译为分布式任务的强大处理能力,以及作为中心化元数据枢纽的服务定位,构建了一个成熟、稳定、高性价比的企业级数据仓库解决方案,是大数据时代不可或缺的核心组件之一。