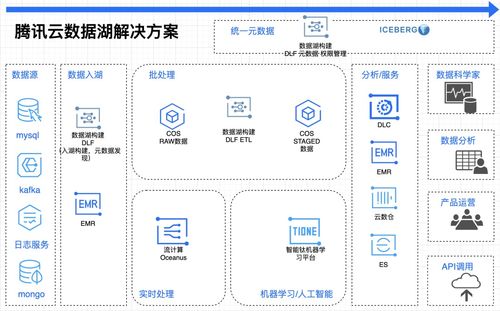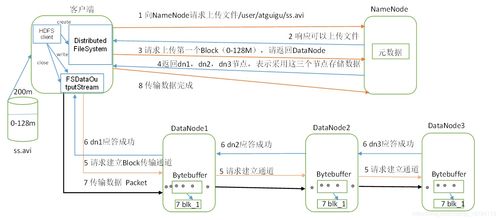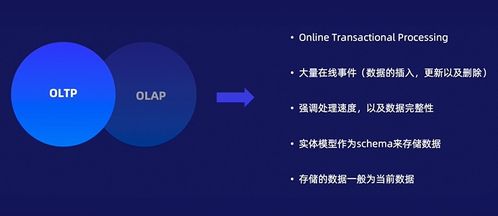
整体流程与核心概念
在数据科学项目中,数据存储与计算是支撑整个数据价值链(从原始数据到业务洞察)的基础设施层。一个典型的流程始于数据采集(如日志、传感器、事务记录),随后数据进入存储系统进行持久化。紧接着,通过计算框架对存储的数据进行清洗、转换、聚合与分析,最终结果可能被推送至应用层(如报表、API、机器学习模型)服务于决策或产品功能。理解这一线性流程是构建高效、可靠数据系统的第一步。
数据库的选型:没有银弹
面对海量数据与多样化需求,数据库选型至关重要。核心考量维度包括:
- 数据结构:
- 关系型数据库(如PostgreSQL, MySQL):适合结构化数据、需要复杂查询、事务一致性(ACID)的场景,如核心业务系统。
- NoSQL数据库:
- 文档型(如MongoDB):适合半结构化、模式灵活的JSON数据。
- 键值型(如Redis):适合高速缓存、会话存储等简单读写场景。
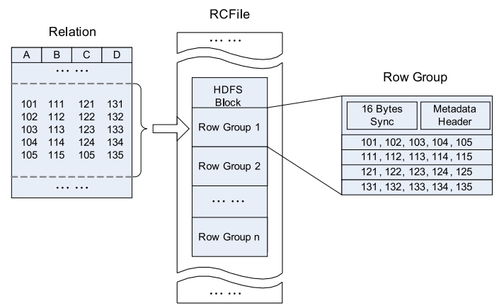
- 列式存储(如Cassandra, HBase):适合大规模、高吞吐的写入与聚合查询(OLAP)。
- 图数据库(如Neo4j):擅长处理高度关联的关系网络数据。
- 读写模式:明确是以高并发写入为主(如日志收集),还是以复杂分析查询为主(如数据仓库)。
- 扩展性:是否需要水平扩展(分片)以应对数据量增长。
- 一致性要求:在CAP定理中,根据业务在一致性(Consistency)、可用性(Availability)、分区容错性(Partition Tolerance)之间的权衡进行选择。
选型建议:现代数据架构常采用多模数据库或混合架构,例如用关系型数据库处理事务,用数据湖(如S3+Hive)存储原始数据,再用列式数据库(如ClickHouse)进行快速分析。
数据处理架构:Lambda vs. Kappa
这是两种主流的流批一体化数据处理架构范式。
- Lambda架构:
- 核心思想:同时维护批处理层和速度层(流处理层)两套计算逻辑。批处理层处理全量历史数据,保证高准确性但延迟高;速度层处理实时增量数据,保证低延迟但可能牺牲一些准确性。两者结果在服务层合并,对外提供统一的数据视图。
- 优点:平衡了准确性与实时性。
- 缺点:需要维护两套代码和计算资源,系统复杂,运维成本高。
- Kappa架构:
- 核心思想:简化架构,只保留流处理层。所有数据(无论历史还是实时)都视为流,通过一个可重播的消息日志(如Apache Kafka)来存储数据。当需要重新计算或纠正逻辑时,只需从日志中重新消费数据进行全量计算。
- 优点:架构单一,只需维护一套代码;简化了开发与运维。
- 挑战:对消息队列的存储容量和回溯能力要求极高;流处理系统需要具备强大的状态管理和精确一次(Exactly-Once)处理语义。
选择建议:对于对实时性要求极高且逻辑相对稳定的场景,Kappa架构更简洁高效。如果业务逻辑复杂且历史数据的重新计算成本非常高,Lambda架构的批处理层仍具优势。如今,随着Flink等具备强大批流融合能力的计算引擎成熟,纯粹的Kappa架构或混合架构成为新趋势。
数据处理和存储服务
云时代,大量托管服务极大降低了数据基础设施的复杂度:
- 存储服务:
- 对象存储:如AWS S3、阿里云OSS,是构建数据湖的基石,成本低、无限扩展,适合存储原始数据、非结构化数据。
- 托管数据库:如Amazon RDS、Azure SQL Database、Google Cloud Spanner,提供自动备份、扩缩容等运维能力。
- 数据仓库:如Snowflake、Amazon Redshift、Google BigQuery,专为大规模分析查询优化,是数据分析的核心。
- 计算服务:
- 批处理:如AWS EMR(托管Hadoop/Spark)、Google Dataproc。
- 流处理:如AWS Kinesis、Google Dataflow、Azure Stream Analytics。
- 无服务器查询:如AWS Athena(直接在S3上运行SQL),实现了存储与计算的分离。
###
数据存储与计算是数据科学的地基。从理解整体流程开始,根据数据特性和业务需求审慎选择数据库类型与处理架构,并积极利用现代化的云服务,可以构建出既敏捷又健壮的数据管线,为上层的数据分析与机器学习应用提供源源不断的可靠燃料。在后续课程中,我们将深入数据清洗、分析与建模的具体实践。